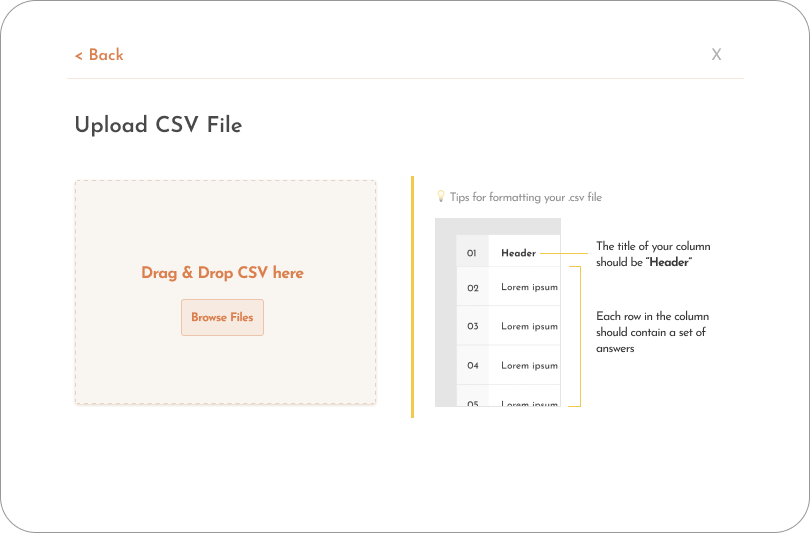
Give clear instructions on formatting within the dataset
When the user is required to upload a dataset necessary to train a model, account for cases where the user does not actually know what a dataset is or entails.
Try to provide clear instructions on what the dataset should include, and how it should be structured.
For CSV
If it is in the form of an excel spreadsheet, tell the user what the model is expecting – 2 columns or 3? Which column should contain the data, and which the labels? Does it matter?
If possible, show examples of an ideal dataset either in pictures or a downloadable sample.

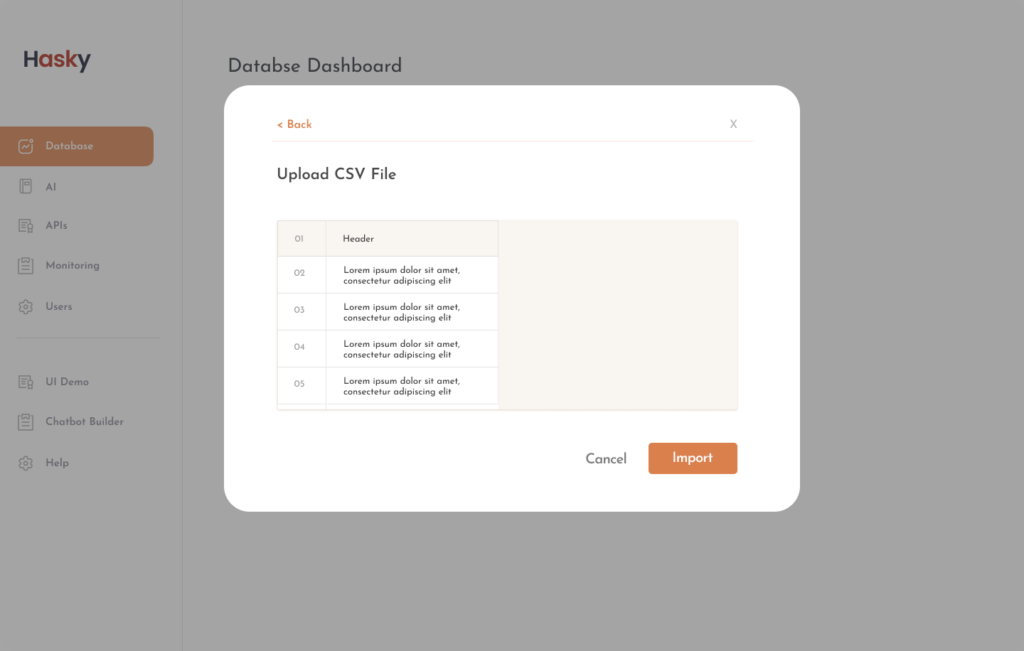
Show preview of uploaded datasets
Once the user has uploaded a dataset, make sure they are able to preview the dataset before moving on to the next step. Often times these users are dealing with multiple datasets and enabling them to double check their uploaded fils reduces any careless mistakes or accidental uploads of the wrong file.